
Moving a Graph RAG System from Neo4j to ArcadeDB — What We Learned the Hard Way- Part 2
We Migrated from Neo4j to ArcadeDB. Here’s Everything That Went Wrong (and Right)

In my previous post, I covered why we had to leave Neo4j GPLv3 licensing implications for our enterprise Graph RAG system, and ArcadeDB’s Apache 2.0 license made it the obvious choice on paper. The pitch was simple: drop-in replacement, Cypher support, Bolt-compatible driver. This post is the technical deep-dive into what happened next.If the first post was about why we moved, this one is about everything ArcadeDB doesn’t tell you until you’re already in it.
Spoiler: it was not a drop-in replacement.
What ArcadeDB Actually Is
Here’s the thing nobody tells you upfront. ArcadeDB is a multi-model database. It supports SQL, Cypher, Gremlin, and MongoDB API. But SQL is its native language. Cypher and Bolt are compatibility layers bolted on (no pun intended) as add-ons.
This matters enormously in practice. When you connect via Bolt and run Cypher, you’re going through at least two translation layers. When you connect via HTTP and run SQL, you’re talking directly to the engine.
The documentation advertises “OpenCypher support.” What it doesn’t prominently mention is which parts of OpenCypher work reliably, which parts are buggy, and which parts silently fail.
The Bolt Problem
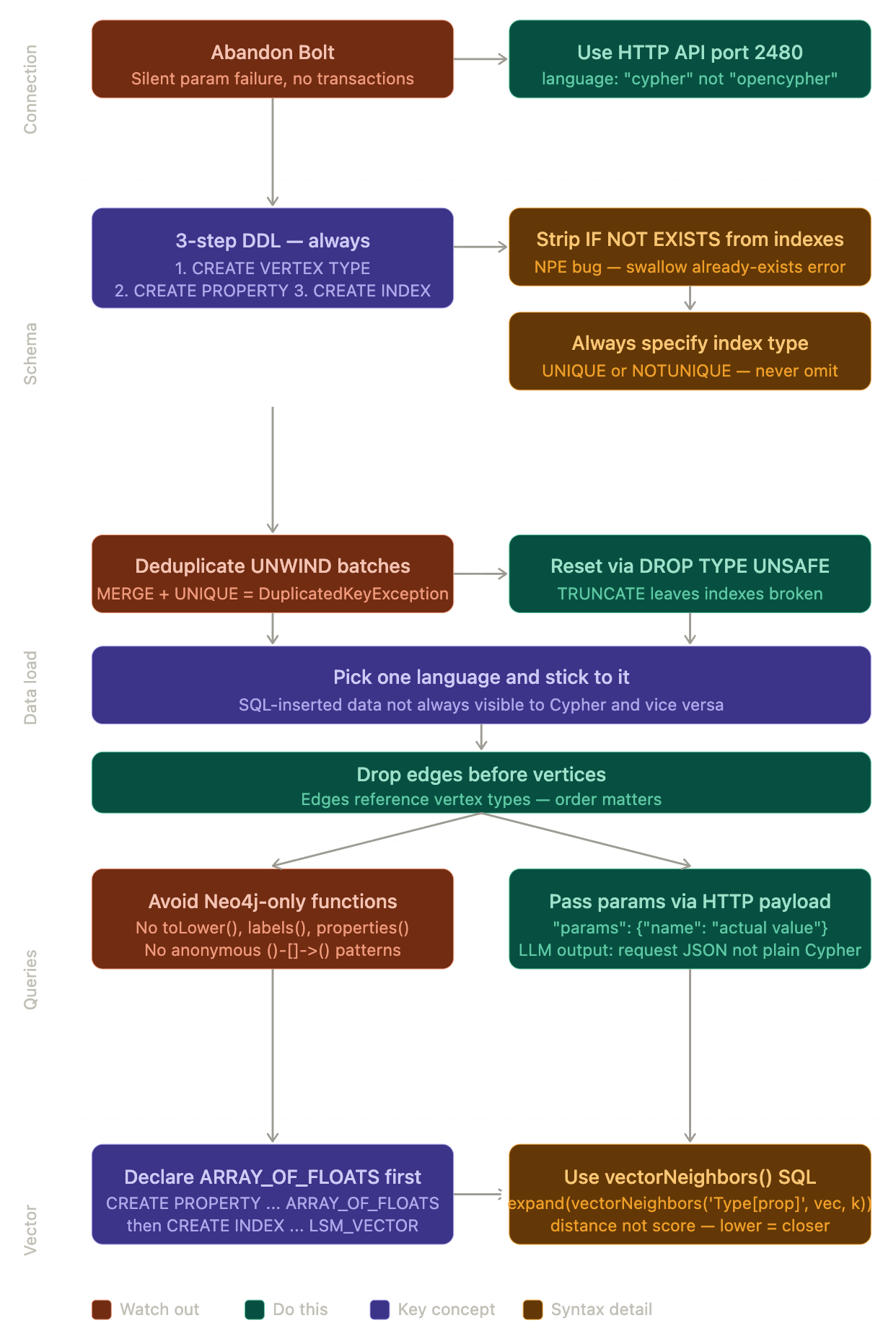
Our first attempt: swap the Neo4j URI to point at ArcadeDB’s Bolt port, keep everything else the same. This is what “drop-in replacement” implies.
What actually happened:
Parameterised queries silently fail. This one cost us a lot. Queries like this would execute but return nothing:
session.run("MATCH (n:Worker {name: $name}) RETURN n", {"name": "John"})
The query ran. No error. Just empty results. We spent days convinced our data wasn’t loading correctly before we realised the parameters weren’t being passed at all. ArcadeDB’s Bolt implementation accepts the query, ignores the parameters, and runs it without them.
session.execute_write doesn’t work. Standard Neo4j transaction pattern:
def _write(tx):
tx.run("MATCH (n) DETACH DELETE n")
session.execute_write(_write)
This throws TransactionNotFound in ArcadeDB. No transactions over Bolt. At all.
DDL over Bolt doesn’t work.
CREATE INDEX, CREATE CONSTRAINT, SHOW INDEXES, SHOW CONSTRAINTS — none of these work over the Bolt connection. They either throw errors or return nothing useful.
The fix: abandon Bolt entirely and move everything to ArcadeDB’s HTTP API. Once we did this, everything became stable. The Bolt driver is essentially decorative in the current ArcadeDB releases.
The HTTP API: Better, But Different
ArcadeDB has a clean REST API at port 2480. Every operation goes through it:
POST /api/v1/command/{database} ← for writes and Cypher
POST /api/v1/query/{database} ← for reads
The key parameter is language. ArcadeDB supports multiple query languages and you must specify which one:
{"language": "cypher", "command": "MATCH (w:Worker) RETURN w LIMIT 5"}
{"language": "sql", "command": "SELECT FROM Worker LIMIT 5"}
{"language": "opencypher", "command": "MATCH (w:Worker) RETURN w LIMIT 5"}
Wait, cypher and opencypher are different? Yes. opencypher is a compatibility shim. cypher is ArcadeDB’s native OpenCypher 25 implementation with actual parameter support.
Always use
"language": "cypher".
Server-side parameters work with the HTTP API:
{
"language": "cypher",
"command": "MATCH (w:Worker) WHERE w.name = $name RETURN w",
"params": {"name": "John Smith"}
}
This works correctly. The parameters are passed to and executed by the engine as expected.
Cypher Compatibility: The Partial Truth
ArcadeDB claims ~98% OpenCypher TCK compliance. In our experience, that number is accurate for the test suite but misleading in practice. The 2% that doesn’t work tends to be things you use constantly.
Things that don’t work in ArcadeDB Cypher:
toLower()— not supported. If you’re doing case-insensitive name matching, you need exact case or you need to normalise data at insert time.labels(node)— throws a parse error. ArcadeDB uses@typein SQL context for the same thing, but@typedoesn’t parse in Cypher context either.properties(node)— not supported. You have to list every property explicitly in yourRETURNclause.Anonymous node patterns —
()-[:REL]->()with no variable names causes problems. Always name your nodes:(a:Person)-[:REL]->(b:Company).Variable-length paths —
[*1..3]is unreliable. Use explicit fixed hops instead.
MERGE + UNIQUE index = hidden bug. This one is subtle and painful. In Neo4j, MERGE on a unique-indexed property correctly matches existing nodes. In ArcadeDB, if the node already exists and you try to MERGE it again within an UNWIND batch where the same key appears more than once, you get:
DuplicatedKeyException: Duplicated key [VALUE] found on index 'Type[property]'
Neo4j handles this gracefully. ArcadeDB doesn’t. You need to deduplicate your batch data client-side before sending it.
Relationship queries need anchoring. This query works in Neo4j:
MATCH (a)-[r:BELONGS_TO]->(b) RETURN labels(a)[0], labels(b)[0] LIMIT 1
In ArcadeDB, labels() doesn’t parse. The workaround for getting relationship endpoint types is to query each edge type individually and use labels(a)[0] which does work when the nodes are typed. It’s inconsistent but workable.
The Index Nightmare
This section alone probably cost us two weeks.
The three-step DDL requirement. In Neo4j, you can index a property that doesn’t exist yet as a schema declaration. In ArcadeDB, you must follow this exact sequence or you get a 500 error:
-- Step 1: Type must exist first
CREATE VERTEX TYPE Worker IF NOT EXISTS
-- Step 2: Property must be declared on the type
CREATE PROPERTY Worker.name IF NOT EXISTS STRING
-- Step 3: NOW you can create the index
CREATE INDEX ON Worker (name) NOTUNIQUE
Skip any step and ArcadeDB throws a SchemaException. There’s no equivalent of Neo4j’s lazy schema inference.
CREATE INDEX IF NOT EXISTS — the NPE bug. We discovered this the hard way. The IF NOT EXISTS clause on CREATE INDEX triggers a NullPointerException in ArcadeDB’s SQL parser:
Cannot invoke "Identifier.getStringValue()" because "this.type" is null
The workaround is to strip IF NOT EXISTS from index creation statements and handle the “already exists” error instead. We wrapped this in a helper that catches the error and swallows it for idempotent DDL.
Index type is mandatory. CREATE INDEX ON Worker (name) fails. You must specify UNIQUE or NOTUNIQUE:
CREATE INDEX ON Worker (name) NOTUNIQUE
CREATE INDEX ON Worker (email) UNIQUE
This seems obvious in retrospect but the error message (NullPointerException on this.type) gives you no clue that the index type is missing.
Constraints don’t exist as a concept. Neo4j has CREATE CONSTRAINT ... REQUIRE property IS UNIQUE. ArcadeDB doesn’t have constraints — uniqueness is enforced via UNIQUE indexes. The mental model is different but the outcome is the same.
TRUNCATE leaves indexes broken. We learned this when trying to reset our database. TRUNCATE TYPE Worker UNSAFE removes the data but leaves the indexes in a state where re-running MERGE queries throws index errors. The correct reset sequence is DROP TYPE (not truncate), which removes the type along with its indexes and properties, giving you a truly clean slate.
-- Correct order: edges first, then vertices (edges reference vertices)
DROP TYPE BELONGS_TO IF EXISTS UNSAFE
DROP TYPE Worker IF EXISTS UNSAFE
The 503 Mystery
Halway through transition, we started getting intermittent 503 errors. We chased this for days through batch size tuning, sleep intervals, queue configuration — nothing worked.
The actual cause, once we found it: MERGE on a UNIQUE indexed property fails with a duplicate key error when the same key appears more than once in the same UNWIND batch. ArcadeDB processes the entire UNWIND transaction atomically, so if your batch contains attributes twice (like org_id = ‘ABC123‘), the second one tries to create it again and hits the UNIQUE constraint.
Neo4j handles this correctly. It matches the existing node on the second occurrence. ArcadeDB doesn’t.
The 503 was ArcadeDB’s HTTP layer converting the DuplicatedKeyException into a server error response rather than a clean exception. Once we deduplicated batches client-side, the 503s disappeared entirely.
The fix pattern:
# Before sending to ArcadeDB, deduplicate within each batch
seen = {}
for row in chunk:
key = row["unique_field"]
if key not in seen:
seen[key] = row
batch = list(seen.values())
Data Visibility Between Languages
This one is architectural and important. ArcadeDB maintains separate visibility between data inserted via SQL and data queried via Cypher.
If you insert data using SQL (INSERT INTO Worker SET name = 'John') and then query via Cypher (MATCH (w:Worker) RETURN w), you might get nothing. The engines don’t always see each other’s data cleanly.
Our solution: pick one language and stick to it for all operations. We chose Cypher via HTTP for everything inserts, queries, everything. This gave us consistent visibility and meant our LLM-generated graph queries worked on the same data the uploaders created.
Vector Search: The LSM_VECTOR Index
We store name embeddings on worker nodes for fuzzy name matching. In Neo4j, vector similarity is a first-class citizen with simple syntax. In ArcadeDB, it requires more setup.
You must declare the property type explicitly before creating a vector index:
CREATE PROPERTY Person.nameEmbedding IF NOT EXISTS ARRAY_OF_FLOATS
Without this, the vector index creation fails with “property does not exist.”
Then create the index with explicit dimensions and similarity metric:
CREATE INDEX ON Person (nameEmbedding) LSM_VECTOR METADATA {dimensions: 768, similarity: 'COSINE'}
The query syntax is completely different from Neo4j:
-- ArcadeDB vector search
SELECT name, distance FROM (
SELECT expand(vectorNeighbors('Person[nameEmbedding]', $queryVector, 10))
) ORDER BY distance ASC LIMIT 10
vs Neo4j’s:
-- Neo4j vector search
WITH $queryVector AS qv
MATCH (w:Person)
WHERE w.nameEmbedding IS NOT NULL
WITH w, vector.similarity.cosine(qv, w.nameEmbedding) AS score
WHERE score >= 0.9
RETURN w.name ORDER BY score DESC LIMIT 10
The semantics are inverted too- ArcadeDB returns distance (lower = more similar) while Neo4j returns score (higher = more similar). Easy to miss if you’re not careful.
What We’d Do Differently
Start with HTTP, not Bolt. If we’d known from day one that Bolt was unreliable, we would have written an HTTP client from the start and saved two weeks. The Bolt compatibility is a nice-to-have for tooling integration but not something to build application logic on.
Test DDL early and exhaustively. The three-step schema creation requirement, the index type requirement, and the NPE bug on IF NOT EXISTS are all things you’d discover in the first hour of serious testing. We discovered them in production-ish environments after spending time writing other code.
Batch carefully. ArcadeDB is not Neo4j when it comes to UNWIND + MERGE. If your data has any duplicates within a batch and you have UNIQUE indexes, you will hit issues. Always deduplicate before sending.
Use SQL for DDL, Cypher for queries. ArcadeDB’s SQL for schema management is solid. Its Cypher for graph traversal is solid. The gap is Cypher DDL, don’t use it.
The Things That Actually Work Well
I’ve been mostly negative so far. To be fair:
Graph traversal queries work correctly. Once you’re past the schema setup, multi-hop graph queries perform well and return correct results. Our 4-hop traversal works cleanly in ArcadeDB Cypher.
The HTTP API is clean and consistent. The REST interface is well-designed and predictable. Once you’re fully on HTTP, the development experience is stable.
Apache 2.0 is genuinely permissive. This is the whole reason we’re here and it delivers on the promise.
ArcadeDB Studio provides a usable web interface (Neo4j browser is just awesome) for running queries and inspecting schema. SQL-based graph traversal with $pathelements does render visually, though Cypher results don’t trigger the graph visualiser.
Multi-model is actually useful. Being able to run SQL SELECT FROM schema:types to inspect schema while using Cypher for application queries is genuinely handy. The two languages complement each other.
The Honest Verdict
ArcadeDB is not a Neo4j drop-in replacement. It’s a different database that happens to speak some of the same languages. If you go in expecting Neo4j behaviour, you will be frustrated.
But if you go in knowing the constraints — HTTP over Bolt, explicit schema management, careful batch deduplication, and language-specific gotchas — it’s a usable graph database with a genuinely permissive license.
For an internal enterprise application where you’re not building a competing database product, the Apache 2.0 license is genuinely valuable. The migration cost was higher than anticipated, but the ongoing licensing clarity is worth it.
This post covers our experience with ArcadeDB 26.4.1-SNAPSHOT. Behaviour may differ in other versions. ArcadeDB is under active development and some of these issues may be fixed in future releases.
Creidt- Blog written with help of Claude andGemini
Hi Piyush,
Thank you for the incredibly detailed write-up. This is exactly the kind of feedback that helps us close the Neo4j-compatibility gap. I'm Luca Garulli, the author of ArcadeDB. You tested against 26.4.1-SNAPSHOT in early May; we're about to cut 26.6.1, and a lot of what you ran into has been addressed in the meantime. A quick status pass on your points:
Already fixed in 26.5 / 26.6
- Parameterized queries over Bolt: fixed; regression tests in `BoltProtocolIT.whereClauseParameterFiltering()` cover string + integer params and WHERE-clause filtering. (issue [#3650](https://github.com/ArcadeData/arcadedb/issues/3650))
- Bolt transactions: fully implemented with proper state machine (BEGIN / COMMIT / ROLLBACK), covered by `transaction()`, `transactionRollback()`, `transactionIsolation()` tests.
- Bolt DDL (`SHOW INDEXES`, `SHOW CONSTRAINTS`): implemented; returns Neo4j-compatible result rows.
- Cypher `toLower()`, `labels()`, `properties()`: all working; `tolower()`/`lower()` aliases both registered. (issue [#3355](https://github.com/ArcadeData/arcadedb/issues/3355))
- Anonymous patterns `()-[:R]->()`: edge-reuse and multi-hop matching bugs fixed (issues [#4098](https://github.com/ArcadeData/arcadedb/issues/4098), [#4115](https://github.com/ArcadeData/arcadedb/issues/4115)).
- `CREATE INDEX IF NOT EXISTS` NPE and missing index-type NPE: both fixed; the parser now returns a friendly message listing the supported index types (issue [#4227](https://github.com/ArcadeData/arcadedb/issues/4227)).
- Variable-length paths: a number of correctness bugs landed in 26.5 ([#3997](https://github.com/ArcadeData/arcadedb/issues/3997), [#3999](https://github.com/ArcadeData/arcadedb/issues/3999), [#4006](https://github.com/ArcadeData/arcadedb/issues/4006), [#4111](https://github.com/ArcadeData/arcadedb/issues/4111), [#4190](https://github.com/ArcadeData/arcadedb/issues/4190), [#4239](https://github.com/ArcadeData/arcadedb/issues/4239)). Multi-hop traversal should be reliable now.
Newly filed from your post (thank you)
- HTTP 503 instead of 409 for `DuplicatedKeyException`: [#4350](https://github.com/ArcadeData/arcadedb/issues/4350)
- SQL MERGE on UNIQUE index with duplicate keys in the same batch: [#4351](https://github.com/ArcadeData/arcadedb/issues/4351)
- TRUNCATE TYPE leaving indexes inconsistent: [#4352](https://github.com/ArcadeData/arcadedb/issues/4352)
- `nodes()`/`relationships()`/`length()` on variable-length patterns: [#4353](https://github.com/ArcadeData/arcadedb/issues/4353)
- Cypher `CREATE INDEX` should infer property type (Neo4j lazy-schema parity): [#4354](https://github.com/ArcadeData/arcadedb/issues/4354)
- SQL/Cypher cross-engine visibility regression tests: [#4355](https://github.com/ArcadeData/arcadedb/issues/4355)
On vector search syntax
I'd treat this as a documentation gap rather than a bug. ArcadeDB exposes `vectorNeighbors()` and returns a distance (lower-is-closer) because the engine supports cosine, dot, L2 and L2² with the same operator surface, and inverted "distance" is the lingua franca across all four. Neo4j's `db.index.vector.queryNodes()` returns a similarity score because it only exposes cosine and dot. Both are correct for their respective scope. We can absolutely do a better job documenting the mapping for migrators, and I'll open a docs task to that effect.
The Bolt driver was indeed thin when you wrote this, but the gap you flagged is what drove the recent push: parameters, transactions, DDL passthrough and integer-property indexing under Bolt all received targeted fixes in the last 6-8 weeks. If you have time to re-test against 26.5.1 (or main), I'd love to know what's still rough.
Thanks again - posts like this are gold for an OSS project.
Luca
Hi Piyush
I see that you have recommended use of cypher instead of openCypher.. However, there is a deprecation notice for cypher on ArcadeDB page..
"ArcadeDB includes two Cypher implementations:
opencypher (NEW) - Native implementation with direct execution. This is the recommended query language for new projects.
cypher (DEPRECATED) - Legacy implementation based on Cypher for Gremlin. This will be removed in a future release."
Hope you have seen this already? https://docs.arcadedb.com/arcadedb/reference/cypher/cypher-introduction